不论是国内 ID 还是国外 ID,解决未激活或者停用,都有一定的失败几率。不能保证 100%成功,但是之前我教了很多人,成功率也有 80%以上。
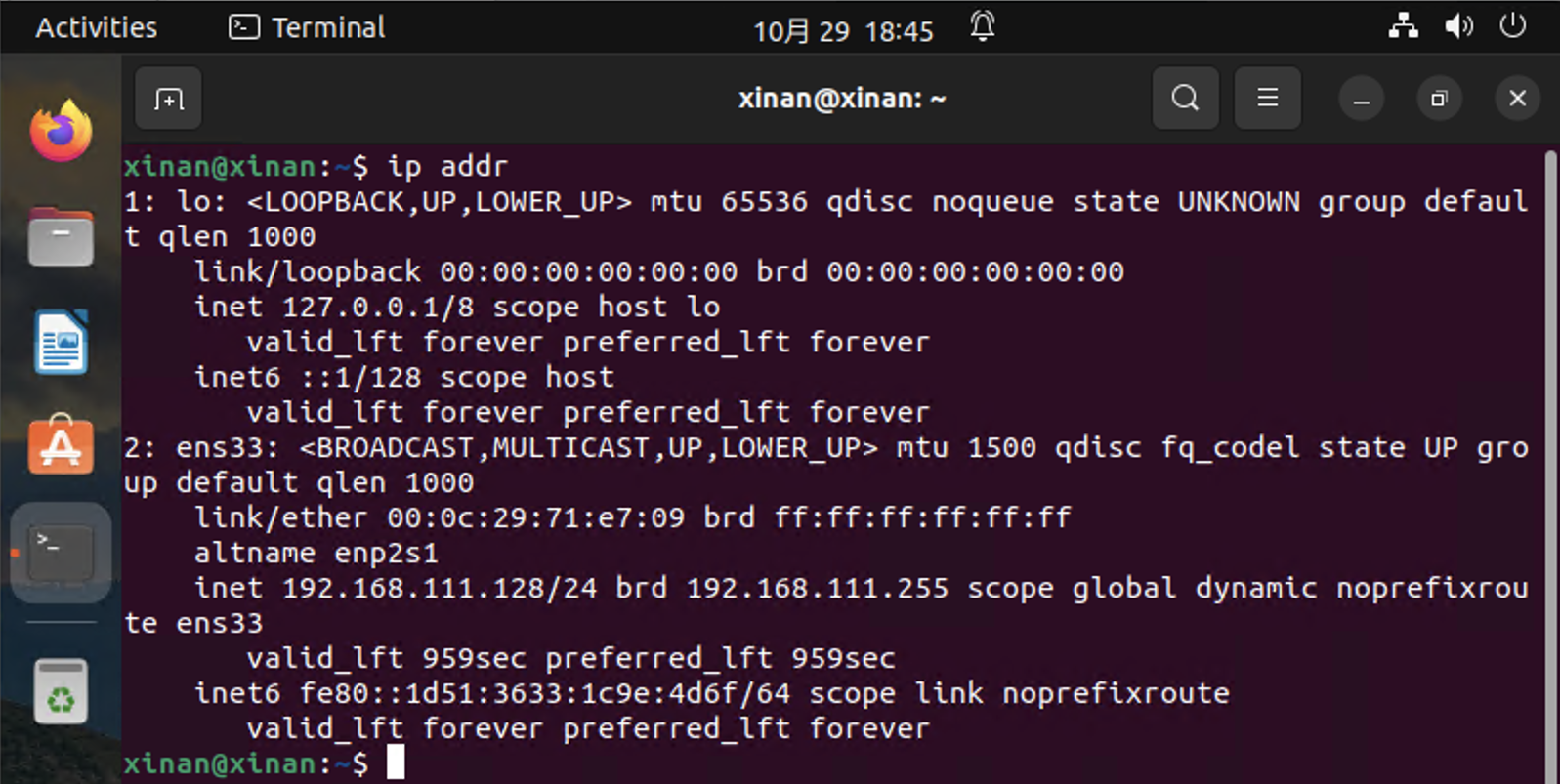
Apple ID 出现“个人不在激活状态”或者“停用”是触发到苹果自检系统的机制。
为了避免这个情况,尽可能的保存好自己的密保和完善账户资料。比如:绑定安全邮箱、修改出生年月日、修改密保问答,让自己的账户变得安全,这样可以减少苹果自检系统的排查!(从 iCloud 登录会大大增加苹果自检系统的排查,所以不要从 iCloud 登录。)
当然完善了这些也有可能排查的到,毕竟你是在大陆使用海外 ID,这本来就不符合苹果的条款规定,对于想下载海外 APP,这一点是无法避免的。甚至就在 6 月份的时候,我 2 个用了近 4 年的海外老账号也被封了,大势已去,我也无法阻挡!
如果是大陆 Apple ID 出现这种情况,直接联系苹果客服 400-666-8800,把自己的事情如实跟客服说,客服能解决就解决,解决不了也没办法。
如果是海外 ID,目前有两种解决方法,第一种是直接电话联系美国苹果总部,电话号码是 001 800 275 2273(需要开通国际漫游、而且需要非常熟练说英语),第二种就是下面我即将要讲解的方法!
不论是国内 ID 还是国外 ID,解决未激活或者停用,都有一定的失败几率。不能保证 100%成功,但是之前我教了很多人,成功率也有 80%以上。
准备工具
1、PC 电脑一台,MAC 也行!
2、谷歌浏览器。(谷歌浏览器带有自动翻译功能,所以这里推荐谷歌,整个过程不需要翻墙)
3、出现问题的海外 Apple ID。(必须记得出生年月日和密保问答资料)
开始解决:
第一步:在谷歌浏览器中打开苹果官网:https://www.apple.com进入官网,把浏览页面滑动到最下面,找到「管理你的Apple ID」点进去。(大家可以看到右下角的国家是“美国”,只有这样进入,才能让联系美国客服,不这样进入,联系的基本是国内客服了。)
第二步:在 Apple ID 管理中心,选择“忘记了 Apple ID 或者密码”!
第三步:选择「FAQ」,这个就是中文的“常见问题”!
第四步:到了常见问题的页面,在最下面点击「请访问 Apple 支持」
第五步:到了 Apple 支持的页面后,继续滑动到最下面,然后点击“得到支持”!(有可能我和你的页面显示的不一样,你可能是英文,所以你可以参考我图片点击也一样的效果)
第六步:进入了“得到支持”的页面后,点击「禁用的 Apple ID」。
第七步:选择“主题未列出”!然后再框框中填写你出现的问题。框框之中必须得使用英文填写,美国客服看不懂!(不会英语的就用“在线汉译英”)
然后再框框中填写你出现的问题。框框之中必须得使用英文填写,美国客服看不懂!(不会英语的就用“在线汉译英”)
第八步:点击聊天室!(有时候可能没有聊天室的时候,那么就是美国苹果客服下班了!美国客服在线时间是:9:00-21:00,以美国加利福利亚现在的时间为准!然后等待时间一般显示 5 分钟的基本是美国客服,如果提示的是 2 分钟,那么就是中国客服,如果是中国客服,你再把之前的操作重新再操作一次)
第九步:把自己出现“个人不在激活状态”通过汉译英后表述给美国苹果客服看!他们问你什么,你就如实回答即可!他们会一步一步的帮你解决!
我并不懂英语!但是他们每问我一个问题。我会立刻使用汉译英来进行翻译,并做出相应的回答!然后客服帮我解封了,之后挂断客服了后,我立刻登录了 ID 到苹果管理中心,发现能正常的登录了,不再提示“未激活”,但是在手机上面登录上后,发现无法下载 APP。提示“在 App Store 与 iTunes Store 里禁用”。之后我又再次以上面的方式联系上了美国客服,他们又帮我解决了这个问题!
感觉整个过程有点复杂,其实自己操作一遍之后,就发现非常的简单了!如果觉得没必要去解除,也可以选择重新再买一个海外 Apple ID。